| Chapter 4 |  |

| Chapter 4 | |
Contents:
Applying Commands in a Script
A Global Perspective on Addressing
Testing and Saving Output
Four Types of sed Scripts
Getting to the PromiSed Land
To use sed, you write a script that contains a series of editing actions and then you run the script on an input file. Sed allows you to take what would be a hands-on procedure in an editor such as vi and transform it into a look-no-hands procedure that is executed from a script.
When performing edits manually, you come to trust the cause-and-effect relationship of entering an editing command and seeing the immediate result. There is usually an "undo" command that allows you to reverse the effect of a command and return the text file to its previous state. Once you learn an interactive text editor, you experience the feeling of making changes in a safe and controlled manner, one step at a time.
Most people new to sed will feel there is greater risk in writing a script to perform a series of edits than in making those changes manually. The fear is that by automating the task, something will happen that cannot be reversed. The object of learning sed is to understand it well enough to see that your results are predictable. In other words, you come to understand the cause-and-effect relationship between your editing script and the output that you get.
This requires using sed in a controlled, methodical way. In writing a script, you should follow these steps:
Think through what you want to do before you do it.
Describe, unambiguously, a procedure to do it.
Test the procedure repeatedly before committing to any final changes.
These steps are simply a restatement of the same process we described for writing regular expressions in Chapter 3, Understanding Regular Expression Syntax. They describe a methodology for writing programs of any kind. The best way to see if your script works is to run tests on different input samples and observe the results.
With practice, you can come to rely upon your sed scripts working just as you want them to. (There is something analogous in the management of one's own time, learning to trust that certain tasks can be delegated to others. You begin testing people on small tasks, and if they succeed, you give them larger tasks.)
This chapter, then, is about making you comfortable writing scripts that do your editing work for you. This involves understanding three basic principles of how sed works:
All editing commands in a script are applied in order to each line of input.
Commands are applied to all lines (globally) unless line addressing restricts the lines affected by editing commands.
The original input file is unchanged; the editing commands modify a copy of original input line and the copy is sent to standard output.
After covering these basic principles, we'll look at four types of scripts that demonstrate different sed applications. These scripts provide the basic models for the scripts that you will write. Although there are a number of commands available for use in sed, the scripts in this chapter purposely use only a few commands. Nonetheless, you may be surprised at how much you can do with so few. (Chapter 5, Basic sed Commands, and Chapter 6, Advanced sed Commands, present the basic and advanced sed commands, respectively.) The idea is to concentrate from the outset on understanding how a script works and how to use a script before exploring all the commands that can be used in scripts.
Combining a series of edits in a script can have unexpected results. You might not think of the consequences one edit can have on another. New users typically think that sed applies an individual editing command to all lines of input before applying the next editing command. But the opposite is true. Sed applies the entire script to the first input line before reading the second input line and applying the editing script to it. Because sed is always working with the latest version of the original line, any edit that is made changes the line for subsequent commands. Sed doesn't retain the original. This means that a pattern that might have matched the original input line may no longer match the line after an edit has been made.
Let's look at an example that uses the substitute command. Suppose someone quickly wrote the following script to change "pig" to "cow" and "cow" to "horse":
s/pig/cow/ s/cow/horse/
What do you think happened? Try it on a sample file. We'll discuss what happened later, after we look at how sed works.
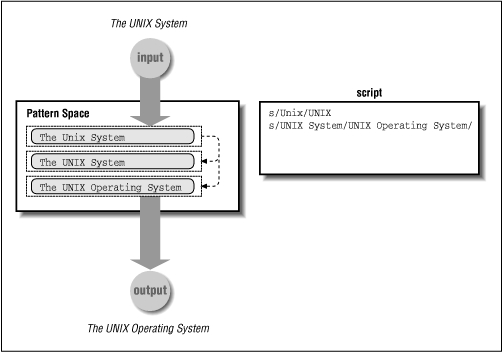
Sed maintains a pattern space, a workspace or temporary buffer where a single line of input is held while the editing commands are applied.[1] The transformation of the pattern space by a two-line script is shown in Figure 4.1. It changes "The Unix System" to "The UNIX Operating System."
[1] One advantage of the one-line-at-a-time design is that sed can read very large files without any problems. Screen editors that have to read the entire file into memory, or some large portion of it, can run out of memory or be extremely slow to use in dealing with large files.
Initially, the pattern space contains a copy of a single input line. In Figure 4.1, that line is "The Unix System." The normal flow through the script is to execute each command on that line until the end of the script is reached. The first command in the script is applied to that line, changing "Unix" to "UNIX." Then the second command is applied, changing "UNIX System" to "UNIX Operating System."[2] Note that the pattern for the second substitute command does not match the original input line; it matches the current line as it has changed in the pattern space.
[2] Yes, we could have changed "Unix System" to "UNIX Operating System" in one step. However, the input file might have instances of "UNIX System" as well as "Unix System." So by changing "Unix" to "UNIX" we make both instances consistent before changing them to "UNIX Operating System."
When all the instructions have been applied, the current line is output and the next line of input is read into the pattern space. Then all the commands in the script are applied to that line.
As a consequence, any sed command might change the contents of the pattern space for the next command. The contents of the pattern space are dynamic and do not always match the original input line. That was the problem with the sample script at the beginning of this chapter. The first command would change "pig" to "cow" as expected. However, when the second command changed "cow" to "horse" on the same line, it also changed the "cow" that had been a "pig." So, where the input file contained pigs and cows, the output file has only horses!
This mistake is simply a problem of the order of the commands in the script. Reversing the order of the commands - changing "cow" into "horse" before changing "pig" into "cow" - does the trick.
s/cow/horse/ s/pig/cow/
Some sed commands change the flow through the script, as we will see in subsequent chapters. For example, the N command reads another line into the pattern space without removing the current line, so you can test for patterns across multiple lines. Other commands tell sed to exit before reaching the bottom of the script or to go to a labeled command. Sed also maintains a second temporary buffer called the hold space. You can copy the contents of the pattern space to the hold space and retrieve them later. The commands that make use of the hold space are discussed in Chapter 6.
|  | |
| 3.3 I Never Metacharacter I Didn't Like |  | 4.2 A Global Perspective on Addressing |